Chinese company DeepSeek has taken the AI world by storm with their recent unveiling of cutting-edge large language models (LLMs), specifically DeepSeek-V3 and its reasoning-focused variant DeepSeek-R1. These open-source models demonstrate performance comparable to leading competitors (Figure A) at roughly 1/10th the training cost and significantly lower inference cost. In simple terms, training cost refers to the expenses incurred in developing and fine-tuning an AI model, including the computational resources, data preparation, and model optimisation required to build the model. On the other hand, inference cost refers to the ongoing costs of running the trained model to make predictions or decisions i.e. when ChatGPT answers users’ queries.
By releasing its models under an open-source license, DeepSeek allows other organisations to replicate and build upon its work. This democratises access to advanced AI technologies, enabling a broader range of entities to develop and deploy AI solutions at a much lower cost. The development raises fundamental questions about the economics of AI: While improved efficiency could accelerate AI adoption, it challenges assumptions about near-term semiconductor demand for training capex, cloud infrastructure spending, and the distribution of value across the technology landscape.
In this article, we examine DeepSeek's key technical innovations, explain how they achieved frontier model performance despite US chip export restrictions, and analyse the broader implications for the technology industry.
Figure A: Benchmark Performance of DeepSeek-R1
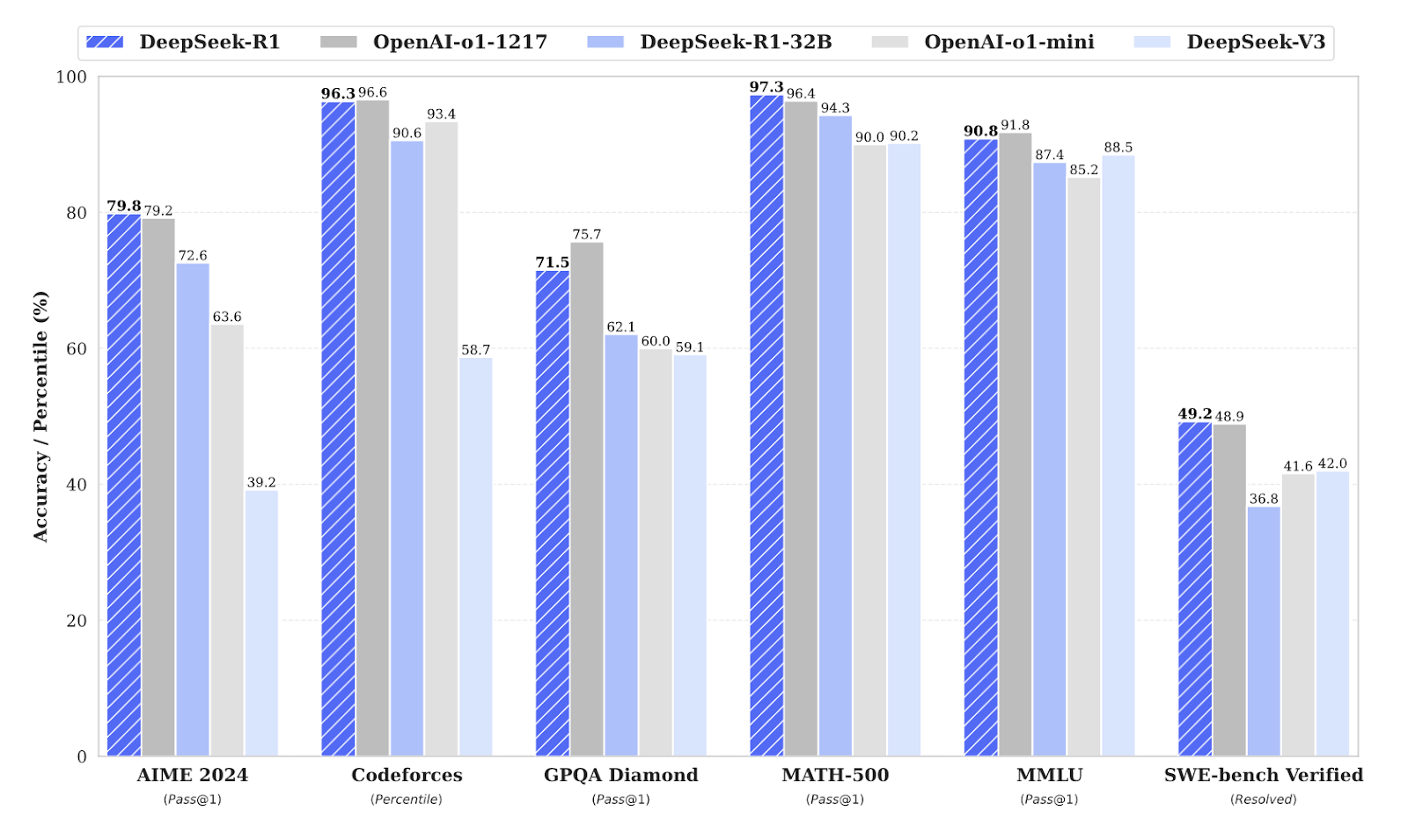
Source: DeepSeek-R1 Technical Report
Market reaction and initial impact
The US stock market awakened to DeepSeek’s disruption in the third week of January. That coincided with the release of DeepSeek-R1 (on 20 January 2025). The model, released under the MIT licence along with its source code, demonstrated exceptional capabilities in reasoning, mathematics, and coding tasks, matching the performance of OpenAI's o1 "reasoning" model at a fraction of the cost. DeepSeek complemented this release with a web interface for free access and launched an iOS application that quickly reached the top of the App Store charts.
Given the US export ban on top-end GPUs to China, which many argued was necessary for the US to maintain its lead in the AI race, the market was shocked to see a China-based frontier model rival the capability of US-based models! By 27 January, as news of DeepSeek's breakthrough gained widespread attention, technology stocks experienced sharp declines, with Nvidia falling 16%, Oracle 12% and smaller AI infrastructure stocks declining 20-30% in a single trading session!
While R1's release finally got the market’s attention, the foundation was laid a month earlier when DeepSeek-V3 was released around Christmas. On 26 December 2024, Andrej Karpathy (formerly Director of AI at Tesla and founding member of OpenAI) highlighted the remarkable achievement: DeepSeek-V3 had reached frontier-grade capabilities using just 2,048 GPUs over two months – a task that traditionally required clusters of 16,000+ GPUs (Figure B). This efficiency gain fundamentally challenged assumptions regarding the computational resources required for developing advanced AI models.
Figure B: Andrej Karpathy on DeepSeek-V3

Source: X
Technical innovations
DeepSeek's efficiency gains arise from several key architectural innovations that fundamentally rethink how large language models process and generate text.
At its core, DeepSeek employs a Mixture-of-Experts (MoE) approach – similar to relying on the most relevant specialist instead of the entire team of doctors when treating a patient. By selectively activating only 37B of 671B parameters for each piece of text (token), the system achieves remarkable efficiency gains. For perspective, Meta's Llama 3 405B required 30.8M GPU-hours, while DeepSeek-V3 used just 2.8M GPU-hours – an 11x efficiency gain. At an assumed cost of US$4 per GPU hour, this translates to roughly US$11.2 million in training costs versus US$123.2 million for Llama 3 405B.
There are several technical innovations worth calling out that focus on efficiency, including:
- Multi-head Latent Attention (MLA): MLA compresses the information required in the “attention” mechanism through low-rank projections. MLA is analogous to a very good summary of a large document. This technique drastically reduces memory demands during inference while retaining the full performance of standard multi-head attention.
- Multi-Token Prediction (MTP): Rather than generating one word (token) at a time, MTP attempts to predict multiple future words simultaneously. This achieves an 85-90% success rate in predicting upcoming tokens, resulting in 1.8x faster text generation.
- Auxiliary-loss-free load balancing: Traditional MoE architectures struggle to balance workload across the “experts.” This is akin to a medical emergency department where some doctors are overworked versus others! DeepSeek-V3 introduced a novel “dynamic bias adjustment” mechanism that ensures balanced expert workloads without compromising performance, achieving 90% expert utilisation.
Prior to DeepSeek’s arrival, many of these architectural and design choices were already known in the research community. For instance, it was well understood that the MoE approach yields 3x to 7x efficiency gains compared to dense models. Nonetheless, DeepSeek managed to push the boundaries of efficiency even further without compromising model quality. By building DeepSeek efficiently without relying on state-of-the-art GPUs, the company demonstrated that necessity is the mother of invention
Reinforcement learning breakthrough
DeepSeek’s R1 technical paper reveals a significant step change in how reasoning capabilities can be developed in LLMs. The widely accepted standard had been to use supervised learning with human-curated datasets followed by reinforcement learning with human feedback (RLHF). DeepSeek, however, showed that sophisticated reasoning can emerge primarily through reinforcement learning alone. In its technical report, DeepSeek notes that its work is "the first open research to validate that reasoning capabilities of LLMs can be incentivized purely through RL, without the need for SFT [Supervised Fine-Tuning].”
The significance of this approach lies in its ability to transcend the limitations of human-demonstrated problem-solving patterns. Traditional supervised learning methods can only replicate reasoning strategies present in the training data. In contrast, DeepSeek's reinforcement learning approach allows the model to discover novel problem-solving strategies through systematic exploration. This is analogous to the difference between learning chess by studying grandmaster games versus learning by playing millions of games and discovering new strategies independently.
Overcoming the US chip ban
DeepSeek’s technical reports also shed light on how the company navigated the U.S. export ban on top-end GPUs like the Nvidia H100. The H800 GPUs available (legally) to DeepSeek significantly reduced NVLink link bandwidth and double-precision computing capabilities. To overcome these limitations, DeepSeek implemented optimisations such as:
- Restricting token processing to groups of 4 GPUs, thus minimising data transfer bottlenecks.
- Developed techniques to handle internal (NVLink) and external (InfiniBand) communication concurrently.
- Implemented FP8 mixed-precision training, halving memory requirements compared to traditional approaches.
- Developed custom kernel software for efficient local expert forwarding.
Investment implications
DeepSeek's innovations will potentially upend how value is created and captured in the AI industry. In this section, we consider some of the potential ramifications of DeepSeek’s innovations, cost efficiency, and release under an MIT license.
At a high-level, DeepSeek’s innovations and cost efficiency are likely to force a re-think on the ravenous appetite for high-end AI accelerators. However, technology history suggests that improved efficiency often leads to increased total resource consumption — a phenomenon known as the Jevons paradox. As barriers to entry fall, more organisations can experiment with and deploy AI solutions, potentially driving higher aggregate demand for AI infrastructure.
Naturally, for semiconductor companies, especially those focused on AI acceleration, these trends present both challenges and opportunities. DeepSeek’s ability to produce a top-grade frontier LLM without access to NVIDIA’s high-end GPUs suggests that some companies might have been complacent with respect to engineering and architectural optimisations, and have instead chosen to use a sledgehammer capex approach to develop increasingly sophisticated models. It is possible that DeepSeek’s success will cause some rethink on this front, which might in turn moderate high-end GPU demand for training capex. This means that companies might be able to do more with their existing GPUs and their useful lives might even be extended. However, the fundamental dynamics of AI development remain compelling: As long as scaling laws hold – where model performance improves as a power-law function of size, dataset, and compute resources – we can expect compute-hungry AI algorithms to require ever more processing power to solve increasingly challenging problems. Moreover, as AI models become more widely available, the demand for inference-optimised semiconductors (inference capex) is likely to grow substantially.
Major cloud providers' current capital expenditure plans suggest confidence in this longer-term vision despite efficiency gains. Microsoft has reiterated its US$80 billion capex commitment, while Alphabet projects approximately US$75 billion in CapEx for 2025, up significantly from US$52.5 billion in 2024. Amazon expects to maintain its Q4 2024 quarterly investment rate of US$26.3 billion through 2025. While it is potentially too early to see strategic shifts in response to DeepSeek's innovations, these investment levels suggest hyperscalers anticipate growing demand for AI compute, and particularly inference workloads. Notably, hyperscalers are positioning themselves as model-agnostic platform providers – evidenced by Microsoft making DeepSeek's R1 available on GitHub and Azure AI Foundry despite its close partnership with OpenAI, and Amazon integrating DeepSeek R1 into its Bedrock and SageMaker platforms.
This evolution signals a broader shift in competitive advantage from raw model capabilities towards proprietary data assets, distribution channels, and specialised applications. Enterprise software businesses, which typically focus on building applications around models rather than developing models themselves, stand to benefit from the widespread availability of high-quality open-source foundation models. As these models improve and become more accessible, competitive advantage will increasingly derive from unique data assets and distribution channels. Enterprises with specialised data repositories, such as Salesforce (CRM data) or Bloomberg (financial data), could develop highly targeted AI agents that leverage their proprietary data advantages.
The platform landscape presents varying implications for different players. Meta appears well-positioned to benefit from LLM commoditisation (a strategy it has followed with its own Llama models), as it can deploy AI innovations to enhance content discovery and user engagement across its vast social networks. Alphabet presents a more complex case: while its Google search advertising model faces potential disruption from AI-powered "answer engines," its YouTube platform and cloud business could benefit substantially from increased AI adoption and deployment.
Obviously, there is a question with respect to where one would undertake the inference task. DeepSeek's approach to providing "distilled" models (1.5B–70B parameters) opens new possibilities for edge computing. These smaller models enable resource-constrained devices to leverage advanced AI capabilities while navigating practical constraints like battery life and thermal limitations. Apple's current hybrid approach — running on-device LLMs for certain tasks while routing others to private cloud infrastructure built using Apple’s M-series silicon – could become the standard blueprint, particularly in consumer applications. This hybrid model effectively balances privacy considerations and response times with computational capabilities.
As the industry evolves, significant uncertainties remain regarding the distribution of economic value between frontier model developers, infrastructure providers, platform companies, and application developers. While investors will need to keep a close eye on these shifting value propositions, and the winners and losers are likely to emerge only in the fullness of time, one aspect appears increasingly clear: We are entering a fascinating phase of AI development. The improved efficiency and accessibility demonstrated by innovations like DeepSeek could democratise access to AI capabilities, potentially making businesses and consumers the ultimate beneficiaries of this technological revolution.
Conclusion
DeepSeek's innovations are not just a technical achievement; they signal a potential restructuring of the AI industry's competitive dynamics. By achieving frontier model performance at roughly 1/10th the traditional training cost and releasing the model under the MIT license, DeepSeek has challenged fundamental assumptions about AI development and deployment.
In this article, we have explored three key implications of this development. First, we have considered the balance between training and inference capex through the lens of Jevons paradox which suggests that lower barriers to entry could drive higher aggregate compute consumption over time. Second, we have considered the potential shift in value creation from raw model capabilities towards data assets, distribution platforms, and specialised applications. Finally, we have contemplated how the emergence of efficient "distilled" models enables new deployment paradigms, from edge computing to hybrid architectures, potentially expanding AI's practical applications.
For investors, there are many nuances to consider including:
- The near-term risks versus medium to long-term opportunities for semiconductor businesses.
- The position of hyperscalers as model-agnostic compute and inference platforms.
- Democratisation of AI models and its effects on enterprise software businesses.
- The pros and cons for platform companies with access to unique data and/or strong distribution channels.
While the geopolitical implications of DeepSeek are still unfolding, the development clearly demonstrates that multiple paths to AI progress exist beyond simply scaling up computing resources and that a path to more democratised AI models is likely feasible. We believe organisations across the spectrum will be reassessing their AI strategies in light of these developments, with perhaps their lens focused on "value addition" and "Return on Investment" rather than raw model size or computing power. In a nutshell, DeepSeek is excellent news for the users of AI and by lowering both the training and inference costs, it has massively increased the Return on Investment (ROI) on AI.
At AlphaTarget, we invest our capital in some of the most promising disruptive businesses at the forefront of secular trends; and utilise stage analysis and other technical tools to continuously monitor our holdings and manage our investment portfolio. AlphaTarget produces cutting edge research and our subscribers gain exclusive access to information such as the holdings in our investment portfolio, our in-depth fundamental and technical analysis of each company, our portfolio management moves and details of our proprietary systematic trend following hedging strategy to reduce portfolio drawdowns.
To learn more about our research service, please visit: https://alphatarget.com/subscriptions/.