

Artificial intelligence (AI) is reshaping industries – from healthcare diagnostics to financial trading – but its transformative power depends on an often-overlooked foundation: AI infrastructure. This specialised ecosystem of hardware, software, and connectivity enables technologies such as chatbots, recommendation systems, and autonomous vehicles to operate effectively.
Unlike traditional cloud computing, which supports general applications such as e-commerce platforms or media streaming, AI infrastructure is purpose-built to meet immense computational demands of machine learning. Training sophisticated AI models, such as large language models (LLMs) that power virtual assistants, requires processing vast datasets across thousands of specialised processors. Deploying these models for real-time tasks, like generating instant recommendations, demands both speed and scalability. This dual challenge — training and deployment — necessitates unique architectural designs optimised for parallel processing, high-speed data transfer, and energy efficiency.
This article explores the core components of AI infrastructure, how it differs from traditional cloud systems, the innovative companies driving its evolution, and the investment opportunities within this dynamic sector. From specialised chips to energy-efficient data centres, AI infrastructure is a critical enabler of technological progress. For investors, it offers a way to gain exposure to AI’s growth through the foundational technologies that will shape industries for decades.
Nuts and bolts of AI infrastructure
AI infrastructure is the technological foundation for building, training, and deploying AI models, particularly large language models (LLMs) that fuel applications ranging from virtual assistants to personalised content recommendations. Unlike general-purpose computing, AI infrastructure is engineered for two distinct phases:
Training: The resource-intensive process of developing an AI model by processing vast datasets to optimise billions of parameters. This phase is comparable to a student spending months mastering complex subjects – requiring significant resources but occurring only once per model version.
Inference: The application of a trained model to deliver real-time outputs, such as answering user queries or generating recommendations. This phase prioritises speed, efficiency, and scalability – similar to a student instantly applying their knowledge across thousands of simultaneous tests.
Next, we examine some of the key components of AI infrastructure (Figure A).
Figure A: AI Infrastructure Abstraction
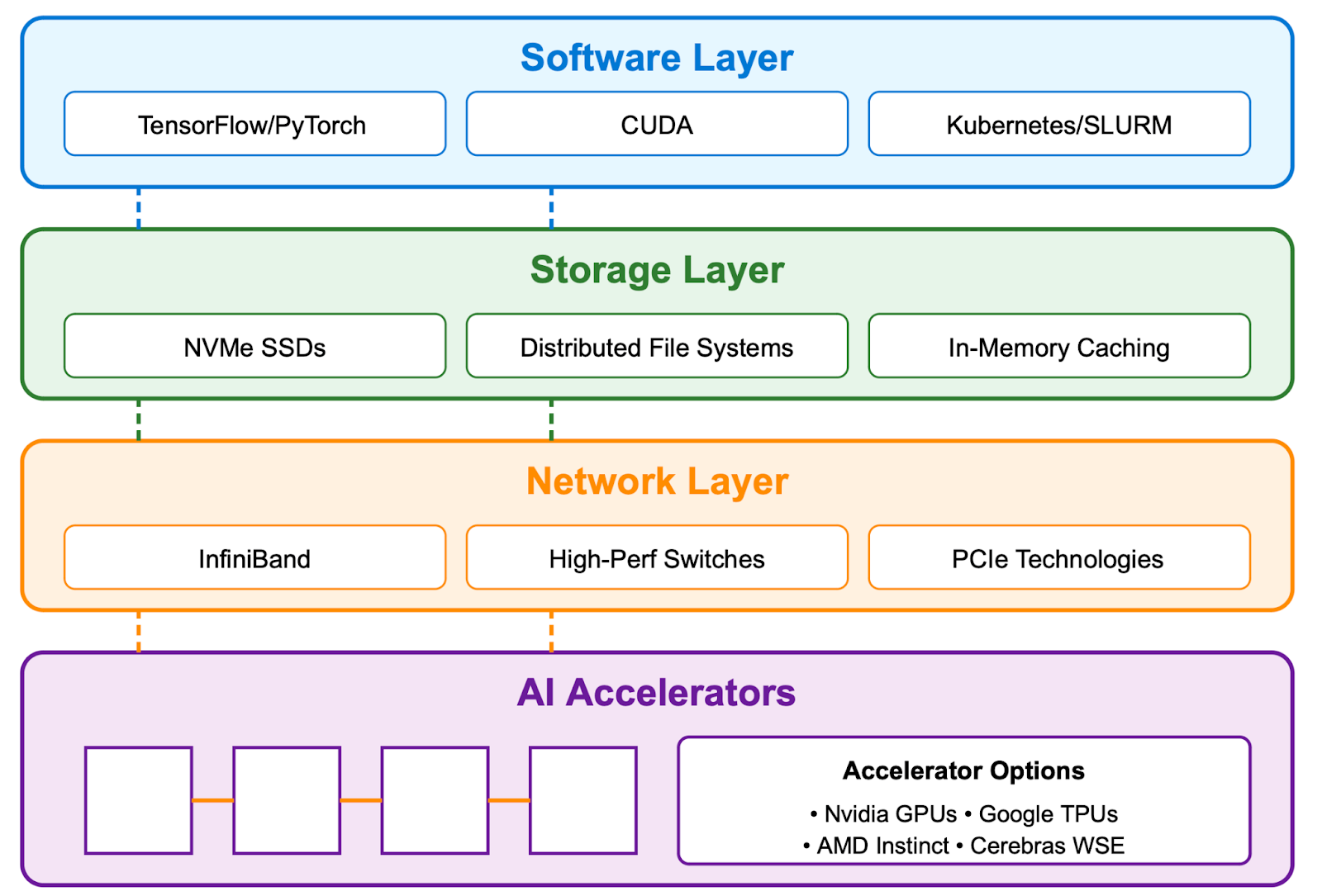
AI accelerators: The computational engine
While traditional computing relies on Central Processing Units (CPUs), AI thrives on specialised accelerators designed for the parallel computations that dominate machine learning workloads.
- Graphics Processing Units (GPUs): Originally developed for graphics rendering, GPUs excel at performing thousands of calculations simultaneously. Nvidia currently leads the market with its Hopper and Blackwell architectures, designed for high-performance AI workloads. Its CUDA software ecosystem is widely adopted, but competitors like AMD (Instinct MI300) and Cerebras (Wafer-Scale Engine) are introducing alternatives that could challenge its position.
- Tensor Processing Units (TPUs): Google’s custom-designed AI chips, optimised for its TensorFlow and JAX frameworks. TPUs are application-specific integrated circuits (ASICs) engineered for machine learning, offering strong performance primarily within Google’s cloud ecosystem.
- Emerging Alternatives: Companies like Cerebras (with its massive Wafer-Scale Engine), AMD (Instinct MI300, focussed on cost-competitive performance), and AWS (Trainium, optimised for cloud training) are challenging Nvidia’s dominance. While these alternatives show promise, it remains to be seen whether they can match Nvidia’s blend of performance and mature software ecosystem.
Storage and connectivity: The data lifeline
While AI accelerators drive computations, storage and connectivity ensure data moves swiftly and seamlessly to support machine learning workloads. These components are vital for training (analysing vast datasets) and inference (delivering instant outputs), serving as the lifeline that keeps AI systems operational.
- High-Performance Storage: AI models demand rapid access to enormous datasets. NVMe Solid State Drives (SSDs) enable swift data retrieval, minimising delays during training and inference. Distributed file systems, such as Lustre or WekaFS, facilitate parallel access to terabytes of data across multiple servers, supporting large-scale AI tasks.
- Advanced Connectivity: AI’s processors require constant, low-latency communication, particularly when thousands operate together. High-speed interconnects, like Nvidia’s InfiniBand, provide rapid data transfer between systems. Specialised switches from providers like Arista and Broadcom manage substantial traffic flows, ensuring smooth coordination across processors. PCIe technologies, essential within servers, enable high-speed connections between GPUs and other components, maintaining efficiency in dense computing environments.
- Emerging Innovations: Novel storage solutions, such as AI-optimised cloud-native systems from AWS and Google Cloud, combine speed and scalability. In connectivity, smart Network Interface Cards (NICs) from companies like Mellanox offload data tasks, improving performance. These advancements aim to rival established systems while addressing AI’s evolving needs.
Together, storage and connectivity form the backbone of AI infrastructure, ensuring data availability and processor synchronisation. Leaders like Pure Storage, Arista, Broadcom, and cloud providers are shaping this critical layer of the intelligence era.
Software ecosystem: The orchestration layer
Hardware alone isn’t sufficient, AI infrastructure requires sophisticated software:
- AI Frameworks: Leading tools like TensorFlow, PyTorch, and JAX provide programming environments for developing and optimising machine learning models.
- Orchestration Platforms: Kubernetes and similar cloud-native orchestration platforms distribute complex workloads across thousands of processors, ensuring scalability.
- MLOps Tools: Specialised tools like MLflow and Kubeflow manage the machine learning lifecycle, from development to deployment and monitoring.
Power and cooling: The physical foundation
The extraordinary computational demands of AI create unprecedented physical challenges:
- Energy Consumption: Large-scale training clusters can consume 10-20 megawatts of power, equivalent to powering approximately 10,000 homes.
- Advanced Cooling: Solutions like direct liquid cooling are essential, as air cooling alone cannot manage the heat generated by dense AI compute clusters.
- Sustainable Design: With rising energy costs and environmental concerns, innovations like renewable energy integration and power-efficient designs are becoming competitive differentiators for infrastructure providers.
The interplay between these components determines the performance and economics of AI infrastructure. For investors, understanding how these elements fit together reveals potential bottlenecks and opportunities across the AI stack.
The rise of specialised AI infrastructure players
The explosive demand for AI compute has driven the emergence of a new breed of technology providers focused exclusively on AI infrastructure. Unlike traditional cloud providers like AWS, Microsoft Azure, and Google Cloud, which serve diverse workloads from web hosting to enterprise databases, these specialised players build infrastructure optimised specifically to meet AI's unique requirements.
Traditional cloud infrastructure, with its general-purpose CPUs and standard networking, was not designed for the intensive matrix calculations of neural networks or the massive data exchanges required by distributed training. While hyperscalers are rapidly expanding their AI offerings, specialised providers have gained momentum by focusing exclusively on optimising for AI workloads — offering superior performance, cost efficiency, and access to scarce compute resources.
A key factor driving this specialisation is the current scarcity of high-performance AI accelerators, particularly Nvidia's coveted H100 and Blackwell GPUs. Access to these chips has become a strategic advantage, with the most successful providers securing multi-year allocations through partnerships with Nvidia. This supply constraint has created a market dynamic where specialised providers with secured GPU supply can command premium pricing and long-term contracts.
In this section, we review some of the key players in this emerging segment.
CoreWeave
CoreWeave operates over 250,000 GPUs in 32 data centers, making it a top provider of AI infrastructure for companies like Microsoft and OpenAI. Its platform uses Nvidia's fast networking and a system called SLURM on Kubernetes to manage workloads efficiently. This setup delivers up to 20% better performance (Model FLOPs Utilisation, or MFU) than competitors, accelerating AI training and processing.
CoreWeave's business is built on long-term contracts, with a US$27 billion backlog (14 times its 2024 revenue of US$1.92 billion) reflecting both the supply-constrained market and customer confidence. These contracts typically span over four years, providing revenue visibility but introducing customer concentration risk, with two clients accounting for 77% of 2024 revenue.
The company's recent acquisition of Weights & Biases enhances its software stack, offering developer tools for model training and positioning it as a full-stack provider rather than merely a hardware operator. CoreWeave has secured Nvidia GPU allocations through partnerships, supporting its global expansion. However, its reliance on Nvidia chips exposes it to supply chain risks, and competitors are exploring alternative accelerators.
Lambda Labs
While privately held Lambda Labs operates at a smaller scale than CoreWeave, it has carved out a niche serving startups, researchers, and small-to-medium enterprises. Its developer-friendly interfaces and on-demand pricing reduces barriers to entry for smaller clients, contrasting with hyperscalers' enterprise-focused models.
Lambda Labs leverages Nvidia GPUs and high-performance networking to support training and inference for mid-scale models. Its focus on accessibility has made it a preferred choice for academic institutions and AI startups, enabling rapid prototyping and experimentation without the burden of long-term commitments.
The company's smaller scale limits its ability to secure large GPU allocations or compete for enterprise contracts, but its agility positions it well for niche segments, particularly in democratising access to AI infrastructure for emerging players.
Nebius
Spun off from Yandex, Nebius has rapidly established itself as a distinctive player in the AI infrastructure market, operating a full-stack AI cloud with 30,000 Nvidia H200 GPUs as of March 2025 and plans to deploy over 22,000 Blackwell GPUs. Its platform, rebuilt in October 2024, integrates in-house hardware, energy-efficient data centres, and software tools like AI Studio – an inference-as-a-service offering with token-based pricing that has attracted nearly 60,000 users since launch.
Energy efficiency is one key differentiator for Nebius. Its Finland data centre features server-heat recovery systems and one of the world's lowest power usage effectiveness (PUE) ratings, significantly reducing energy costs. The company's proprietary servers, designed to operate at higher temperatures (40°C) with air cooling, lower maintenance costs and enable faster deployment.
On the software side, Nebius offers Soperator, a SLURM-based workload manager that optimises job scheduling, while its MLOps suite streamlines the AI lifecycle. Targeting developers, AI labs, and enterprises, Nebius is expanding in Europe and the U.S., with a focus on data sovereignty, which could be a strategic advantage in regulated markets.
Cerebras
Cerebras Systems, which is in the process of going public, takes a fundamentally different approach with its Wafer-Scale Engine (WSE), a massive chip integrating compute, memory, and interconnects for AI training and inference. Unlike GPU-based providers, Cerebras offers up to 10x faster training for certain LLMs compared to GPU clusters by eliminating much of the communication overhead inherent in distributed systems.
Its CS-3 system, powered by the third-generation WSE, competes with Nvidia's DGX clusters for frontier AI research, while its Condor Galaxy supercomputers provide exascale compute for global AI development. Cerebras' integrated hardware and software approach simplifies model development but targets a premium segment focussed on ultra-large models.
The current market heavily favours providers with access to Nvidia’s high-end GPUs, which are in short supply due to their dominance in AI workloads. This scarcity gives CoreWeave, Nebius, and Lambda Labs a competitive edge, as their GPU allocations attract clients unable to secure chips directly. However, the rise of alternative AI accelerators – like Cerebras’ WSE, AMD’s Instinct MI300, Google’s TPUs, and AWS’s Trainium – could disrupt this dynamic. If these accelerators match or surpass Nvidia’s performance, demand for Nvidia GPUs could slow, favouring hyperscalers with broader infrastructure, diverse chip portfolios, and greater financial resources to integrate alternatives. Hyperscalers’ economies of scale and established client bases could outpace specialised providers in a less supply-constrained market. Additionally, the capital intensity of scaling GPU clusters and data centres remains a significant barrier, requiring substantial debt financing and exposing providers to financial risks – especially if market dynamics shift.
Further, it is important to consider the broader risks facing these specialised AI infrastructure pure plays. Demand uncertainty looms, as long-term monetisation of AI applications remains unproven, potentially leading to industry consolidation around hyperscalers if GPU supply normalises. Customer concentration, such as CoreWeave’s reliance on two clients for 77% of 2024 revenue, introduces volatility. Capital intensity for expanding infrastructure, coupled with geopolitical factors like U.S.-China chip export restrictions and data sovereignty laws, could disrupt supply chains.
Energy constraints, too, are becoming critical, with AI’s massive power demands straining grids, necessitating sustainable solutions. These hurdles require specialised providers to innovate continuously while navigating a competitive, capital-intensive environment.
Sizing the opportunity
According to industry analysts, the AI infrastructure market is likely to experience rapid growth, driven by surging demand for high-performance computing and widespread AI adoption. Efficiency gains are accelerating this expansion, as lower costs enable broader deployment. This phenomenon is known as the Jevons Paradox – the idea that increased efficiency drives higher resource consumption.
As shown in Figure B, Precedence Research projects that "the global artificial intelligence infrastructure market size will grow from US$47 billion in 2024 to USD 499 billion by 2034 (CAGR of 26.60%). North America currently leads with US$19.36 billion in 2024, driven by innovation, mergers, and hyperscaler investments. The report highlights particularly strong growth in inference infrastructure, projected at a 31% CAGR compared to 23% for training infrastructure, reflecting the broader deployment of AI applications across sectors.
Figure B: The AI Infrastructure Market Opportunity

Source: Precedence Research, February 2025.
Morgan Stanley, in a recent report, offers an even more aggressive outlook, projecting cumulative AI infrastructure spending exceeding US$3 trillion by 2028, with US$2.6 trillion allocated to data centers (chips and servers).
Further, it appears we are approaching what could be called an "Inference Inflection Point" in the market. While media attention and investment have concentrated on training infrastructure – driven by GPU scarcity and the prestige of foundation model development – the long-term volume opportunity is increasingly shifting toward inference.
This inflection point could significantly shift competitive dynamics in the coming years. Providers with global distribution, energy-efficient designs for sustainable scaling, and flexible pricing models may capture disproportionate value as inference workloads explode. For investors, this suggests looking beyond today's training-dominated headlines to identify companies well-positioned for the expanding inference market that will follow the current training-focussed boom.
We can already see strategic positioning for this shift among the major players. CoreWeave, while currently focused on training contracts, is expanding its inference capabilities. Nebius has aggressively developed its AI Studio platform specifically targeting inference workloads with token-based pricing. Even Cerebras, despite its high-end training focus, is exploring how its architecture can serve certain inference applications efficiently.
Conclusion
AI infrastructure is a cornerstone of the intelligence era, enabling transformative technologies through specialised hardware, advanced connectivity, and tailored software. Its evolution from traditional cloud computing marks a pivotal shift, driven by the demands of training and inference.
Specialised providers such as CoreWeave, Lambda Labs, Nebius, and Cerebras are redefining the landscape with innovative designs and full-stack solutions, but success hinges on several critical factors.
Key considerations for the sector’s future include:
- The pace of AI adoption and the scalability of infrastructure solutions across industries.
- Innovations in energy efficiency, connectivity, and hardware to address power and performance constraints.
- Competition between hyperscalers and specialised providers, differentiated by pricing, software, and niche expertise.
- Geopolitical and regulatory developments impacting supply chains and market access.
The likely winners will be companies that balance technological innovation with practical scalability, addressing enterprise needs while navigating capital and energy constraints. The opportunity extends beyond infrastructure providers to the broader ecosystem of semiconductor, software, and edge computing players.
AI infrastructure represents a transformative force, but its path forward requires careful analysis of technological capabilities, market dynamics, and disciplined execution.
At AlphaTarget, we invest our capital in some of the most promising disruptive businesses at the forefront of secular trends; and utilise stage analysis and other technical tools to continuously monitor our holdings and manage our investment portfolio. AlphaTarget produces cutting edge research and our subscribers gain exclusive access to information such as the holdings in our investment portfolio, our in-depth fundamental and technical analysis of each company, our portfolio management moves and details of our proprietary systematic trend following hedging strategy to reduce portfolio drawdowns. To learn more about our research service, please visit https://alphatarget.com/subscriptions/.


