

“I think in terms of the AI, the biggest challenge I think for a lot of my customers is memory. Memory actually there’s no relief as far as I know when I talked to the you know, only three key players, two of them I talked to very frequently, and then they told me, ‘Lip-Bu, there’s no relief until 2028.’”
Lip-Bu Tan, Intel CEO, February 2026 (Cisco AI Summit)
Introduction
Memory has emerged as one of the hottest sectors in technology, driven by the explosive growth in AI infrastructure build-out. Memory has become a critical bottleneck in AI systems across both training and inference. With demand rising far faster than supply can respond, memory prices have risen sharply, driving strong growth in revenues and profits across the memory industry. The three main players, SK Hynix, Samsung and Micron, have all benefited tremendously, with their share prices rising roughly 3-4x over the past year. All three have also sold out their entire AI GPU memory production for 2026, and the overall memory market is now forecast to grow by 134%, to US$552 billion (TrendForce forecast), by the end of the year.
“They've seen boom and bust 10 times. That's a lot of layers of scar tissue. During the boom times, it looks like everything is going to be great forever. Then the crash happens and they're desperately trying to avoid bankruptcy.”
Elon Musk, February 2026 (Dwarkesh Patel Podcast)
Despite the strong industry tailwinds, however, both memory producers and investors are still haunted by the boom-and-bust cycles of the past. The key question now is whether history will repeat once again, or whether this is a new normal, with the AI secular trend sustaining elevated economics and ushering in a memory golden age.
In this note, we first provide a market overview of the memory industry, highlighting different memory types and company market shares. Next, we examine why memory is essential to AI training and inference and how it has emerged as a major bottleneck. We then outline some steps taken to mitigate these constraints. We next present a case study of SK Hynix, focusing on its recent performance and future growth. We also discuss the spillover effects from memory shortages on other sectors, including smartphones and PCs. Finally, we provide a market outlook and discuss the sector risks.
The memory landscape
Different types of memory can be viewed as a hierarchy, often illustrated as a pyramid (Figure 1). At the top sits the fastest memory, with the highest bandwidth, where bandwidth refers to how much data can be moved per second and is typically measured in GB/s or TB/s. However, this top-tier memory also has the highest cost and the lowest capacity, where capacity refers to how much data it can hold and is typically measured in GB or TB. As you move down the pyramid, bandwidth falls while capacity rises and cost per bit declines.
Figure 1: The Memory Pyramid Hierarchy (Simplified)
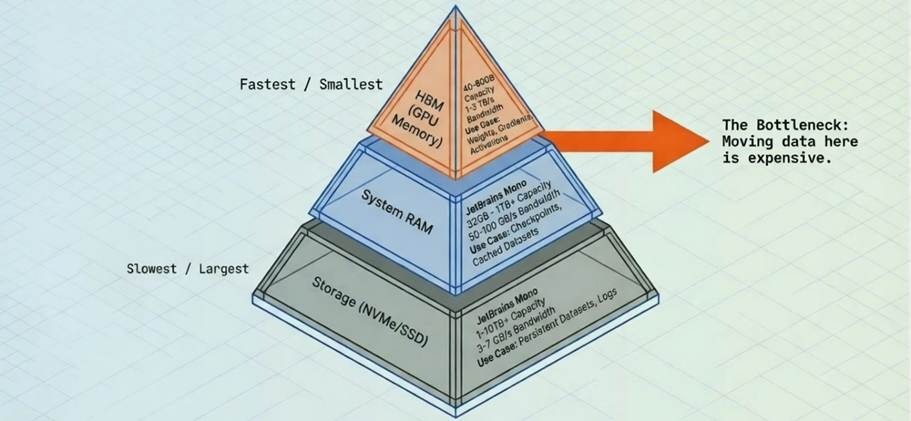
Source: Sam Mokhtari
The memory market is dominated by two categories: DRAM and NAND flash. DRAM is the principal memory technology used for active computing workloads and is much faster than NAND, but it is also more expensive per bit and typically offers less capacity. NAND, by contrast, is used primarily for storage applications such as SSDs and offers much higher capacity at lower cost, but with much lower speed.
Figure 2: Global DRAM Market Share by Revenue
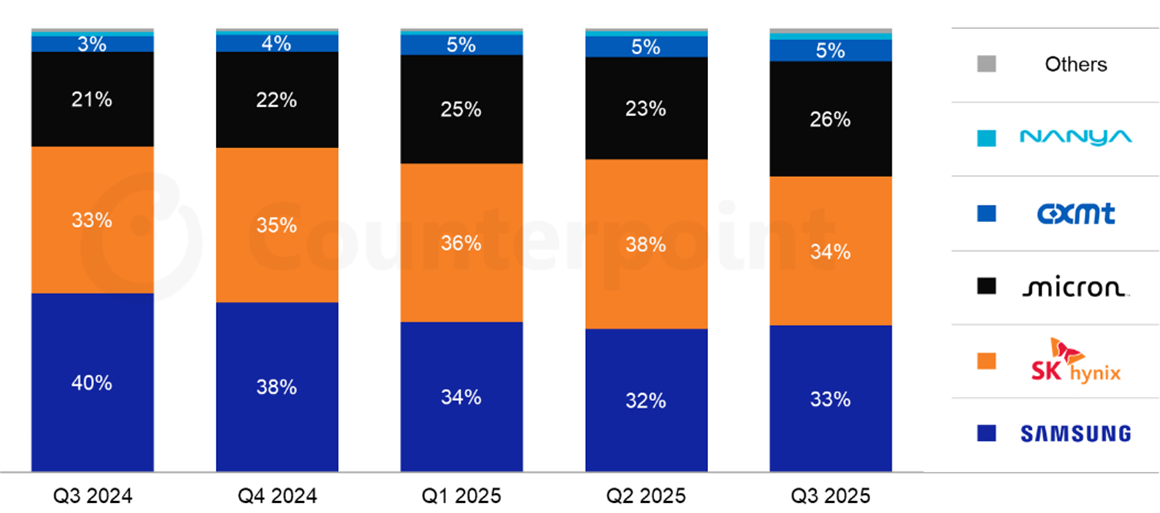
Source: Counterpoint Research
Within DRAM, there are several sub-types. Conventional DRAM typically serves as CPU-attached system memory, while High-Bandwidth Memory (HBM) is a specialised variant of DRAM used in AI GPUs. HBM provides much higher bandwidth than conventional DRAM and is essential for keeping GPUs fed with data during active computation. SK Hynix is currently the leader in HBM and a major supplier to Nvidia (Figure 3).
Figure 3: Global HBM Market Share by Revenue
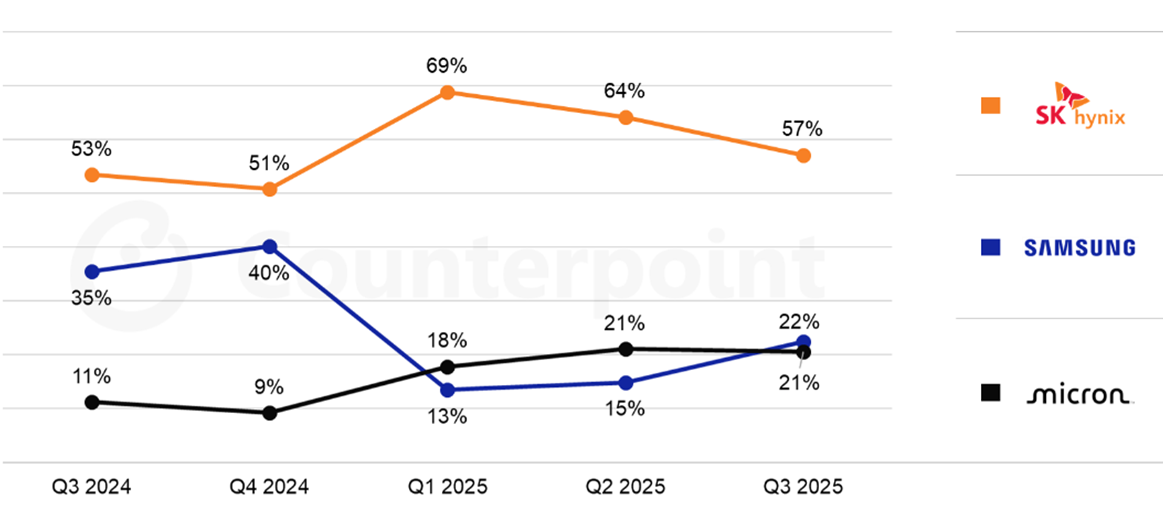
Source: Counterpoint Research
The memory bottleneck
The reason memory has become such a critical focus in AI is that it is now a key bottleneck to further progress, due to both bandwidth and capacity constraints.
The bandwidth bottleneck stems from GPU compute power having improved at a faster rate than memory bandwidth over the past decades. This divergence has compounded considerably, leading to a significant gap. This is illustrated in the chart below, where compute speed (hardware FLOPS) outgrew memory speed (DRAM bandwidth) by a factor of 600x over a 20-year period (Figure 4).
In practice, this means GPUs frequently finish their calculations and then sit idle waiting for the next batch of data to arrive from memory. The result is expensive GPUs left underutilised and slower model training. The bandwidth bottleneck is also known as the “memory wall,” a term originally coined in 1995 by William Wulf and Sally McKee to describe the growing gap between processor speeds and memory performance. While it originally described the growing gap between processor speeds and memory performance, the term is now used more broadly to encompass capacity constraints as well.
Figure 4: The memory wall
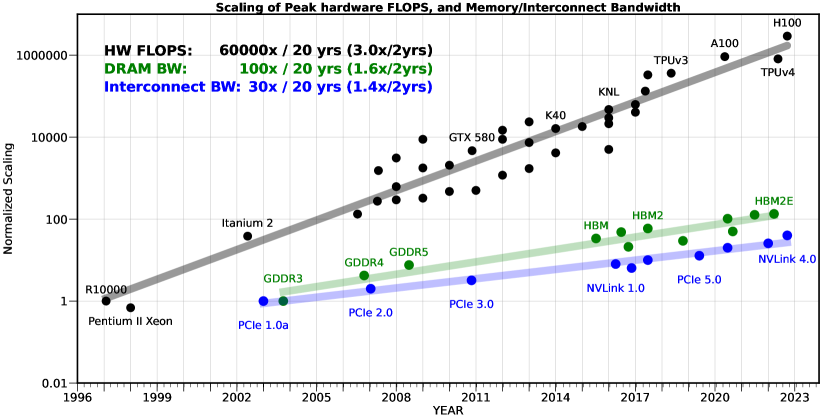
Source: Gholami et al., 2024, "AI and Memory Wall"
The capacity bottleneck has also become a major limiting factor. Training large models requires storing not just the parameters (the core learned weights), but also gradients (signals for updating weights), optimiser states (extra data used to enhance and stabilise updates) and activations (temporary intermediate results used to compute gradients) (Figure 5). Therefore, limited memory capacity acts as a bottleneck for building more powerful models. Similarly, it can also limit inference performance, as longer context windows exhaust available GPU memory.
Figure 5: Memory breakdown example of a 7 billion parameter model
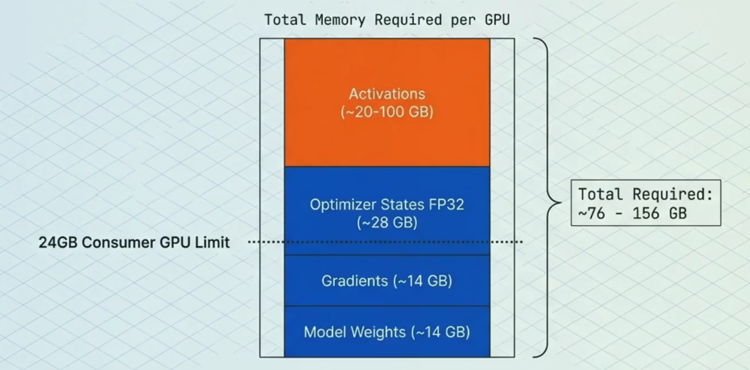
Source: Sam Mokhtari
Solving the bottlenecks
A range of optimisations have been adopted to address these bottlenecks. This includes “Precision Reduction,” which entails storing data in GPU memory in lower precision formats (e.g. FP32 vs FP16), reducing both memory capacity and bandwidth required. A further optimisation is the use of “Parallelism”, which allows the memory that would normally sit on a single GPU to be split across multiple GPUs, enabling larger models.
A third and particularly consequential development is "Key-Value (KV) cache offloading." KV cache is a data structure created during inference and grows linearly with prompt length. For use cases such as multi-turn conversations, deep research and code generation, limited and costly GPU memory becomes a significant constraint, especially when the KV cache must be retained in memory for extended periods. KV cache offloading solves this by progressively moving less-active portions of the cache from the GPU’s limited HBM first to CPU DRAM (system memory) and then to SSD storage as the cache grows. This hierarchical approach eases the capacity bottleneck for longer contexts without requiring additional GPUs, while keeping the most frequently used (“hot”) data in the fastest memory tier. The surge in inference workloads and wider adoption of KV cache offloading have, in turn, driven a sharp rise in demand for conventional DRAM and NAND.
Beyond these system-level techniques, architectural innovations are also reducing memory intensity per unit of AI capability. Mixture of Experts (MoE) models, such as those used by DeepSeek and Mistral, activate only a fraction of the model's total parameters on any given forward pass. This means a model with hundreds of billions of parameters may only require memory bandwidth for a small subset during each computation, significantly easing both bandwidth and capacity demands relative to a dense model of equivalent capability. Similarly, distillation, namely the process of training smaller, more efficient models to replicate the outputs of larger ones, is producing compact models that deliver strong performance with a fraction of the memory footprint. Together, these developments mean that useful AI capability is growing faster than raw memory consumption, which has important implications for the demand outlook.
On the hardware side, Processing-in-Memory (PIM) represents an emerging approach that differs fundamentally from the software-level optimisations above. Rather than accepting the separation between compute and memory and working around it, PIM integrates computational capabilities directly into the memory itself, reducing the need to move data back and forth. SK Hynix (see next section) showcased several PIM-related technologies at CES 2026, including an accelerator card prototype specialised for large language models and a Compute-using-DRAM product. The HBM4 standard itself is a stepping stone in this direction, introducing a logic base die manufactured using a logic process rather than a traditional DRAM process, enabling basic computational tasks to be performed on-die. Industry experts view this as a pivotal early step toward fuller PIM integration, with specialised AI processing units expected to be embedded directly into HBM logic dies by 2027.
Although these optimisations help reduce bottlenecks, they still come with trade-offs, such as potential accuracy losses or added complexity. And still, the memory bottleneck persists, as the appetite for higher bandwidth speeds and more capacity remains insatiable. While the memory suppliers are investing heavily to meet these demands, it takes time to respond, as bringing new state of the art fabrication plants (fabs) online is typically a five-year period when factoring in the time for construction, tool installation and yield ramp. As such, there does not appear to be any near-term solutions to fully solving the current bottlenecks.
SK Hynix case study
SK Hynix saw strong growth in FY2025, with overall revenue up 47% year-over-year (Figure 6) and HBM revenue more than doubling and making a significant contribution. There was also strong growth in conventional DRAM and NAND, driven to a large extent by growth in inference and the use of KV cache offloading. Operating profit for the year grew 101%, driven largely by price increases.
Figure 6: SK Hynix revenue and profit growth
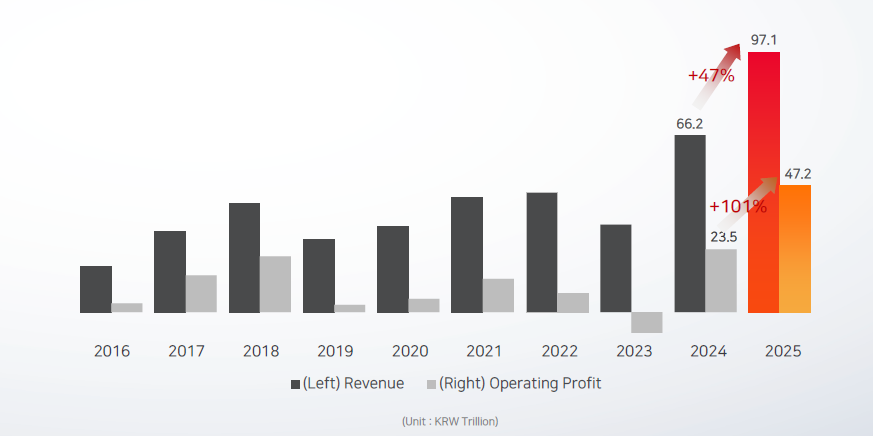
Source: SK Hynix
Zooming in on the Q4 2025 results (Figure 7), there was particularly strong acceleration here, with revenue up 66% year-over-year and up 34% sequentially quarter-over-quarter. The Q4 sequential growth was driven largely by DRAM average selling price (ASP) increasing in the mid-20s%, and to a lesser extent by DRAM shipment growth (bit growth), which only grew in the low single digits. Shipment growth was driven by both HBM3E products and DDR5 for servers, where shipment of high-density DDR5 modules were up by roughly 50% quarter-over-quarter. NAND also saw strong revenue growth, with sequential ASP growth in the low 30s% and shipments up roughly 10%.
Figure 7: SK Hynix revenue by product and application
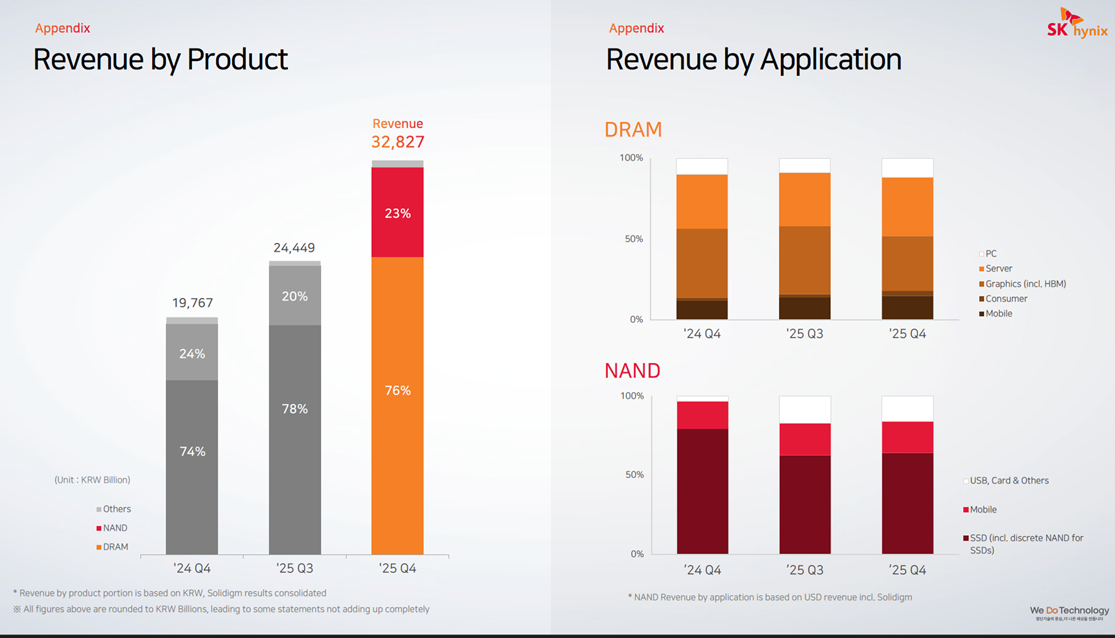
Source: SK Hynix
For FY26, SK Hynix has already secured full customer demand for its entire DRAM and NAND production and remains capacity constrained. DRAM bit shipments are guided to grow over 20% and NAND is guided to grow in the high teens%. Its new Cheongju M15X fab is currently on track to begin mass HBM production in H1 2026 and FY26 CAPEX is also set to increase considerably as it continues to invest in new fabs to expand production capacity. SK Hynix is also expected to maintain its leadership in HBM3E whilst simultaneously ramping up its next-generation GPU memory, HBM4, which started mass production in September 2025. HBM4 can process over 2 TB/s versus 1.2 TB/s for HBM3E and has a power efficiency improvement of more than 40%. Overall, analysts still expect HBM3E to make up two-thirds of total HBM shipments in 2026, with SK Hynix maintaining its market leading position. Analysts also expect SK Hynix to achieve roughly 70% market share for HBM4 in Nvidia’s next-generation Rubin platform.
Spillover effects in other sectors
“The AI-driven growth in the data centre has led to a surge in demand for memory and storage. Micron has made the difficult decision to exit the Crucial consumer business in order to improve supply and support for our larger, strategic customers in faster-growing segments.”
Sumit Sadana, Micron EVP and Chief Business Officer (December 2025)
“PCs and mobile devices are expected to see short-term shipment adjustments due to rising component costs and weakened consumer sentiment. Memory content per device is expected to grow at a slower pace due to price increases and supply constraints.”
Song Hyun Jong, SK Hynix President (Q4 2025)
The memory supply-demand imbalance is also impacting other sectors, including smartphones and PCs. Memory manufacturers are prioritising lucrative AI-grade DRAM over traditional DRAM, creating pricing pressure across consumer electronics. As a result, IDC estimates that the smartphone market will shrink 2.9% in terms of shipments year-over-year in 2026. It also expects that prices will have to rise significantly or specifications will have to be cut, or both. Furthermore, it expects the lower-end smartphones with thin margins to be impacted most severely. For high-end smartphones like Apple and Samsung there is also expected to be pressure, though they will likely be more insulated due to long-term supply contracts and market power. For the PC market, IDC expects even deeper disruption, with shipments forecasted to fall 4.9% (Figure 8). IDC also expects PC vendors with larger volumes to be better positioned and to take share away from the smaller, more vulnerable brands.
Figure 8: PC Market Forecast Scenarios
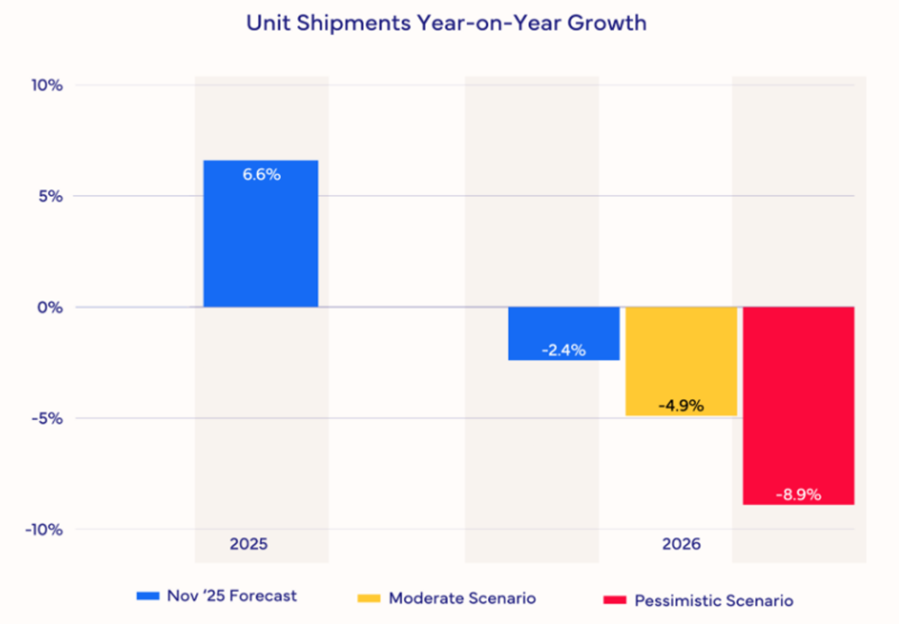
Source: IDC
Short to medium term outlook
In the short- to medium-term, market forecasts for the memory sector differ materially, largely reflecting the high uncertainty around pricing levels. Additionally, given how rapidly the space is evolving, forecasts are frequently being revised. In its most recent forecast, TrendForce revised its numbers upward significantly and now expects Q1 2026 conventional DRAM contract prices to rise 90-95% and blended HBM price to be up 80-85%, quarter-over-quarter (Figure 9).
Figure 9: Memory Price Growth Forecasts 4Q25-1Q26
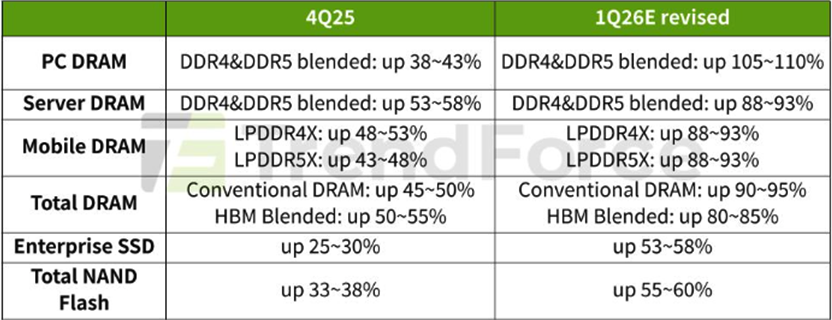
Source: TrendForce
For the overall memory market (DRAM + NAND) in 2026, TrendForce forecasts 134% revenue growth, reaching a market size of US$551.6 billion (Figure 10). For 2027, it forecasts 53% growth, reaching a market size of US$842.7 billion.
Figure 10: DRAM and NAND Flash Revenue Projections
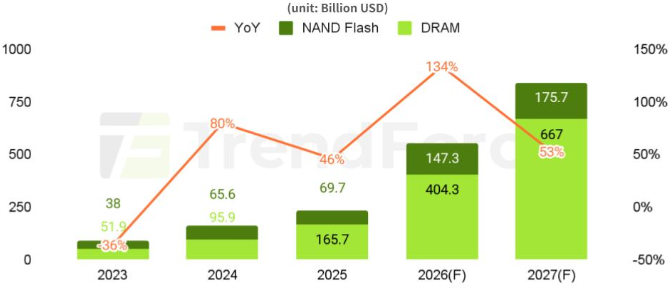
Source: TrendForce
On HBM bit shipments, SemiAnalysis forecasts that Nvidia will still dominate demand, while Broadcom, Amazon and AMD are also expected to grow their shares significantly (Figure 11).
Figure 11: HBM Bit (shipments) Demand Forecast
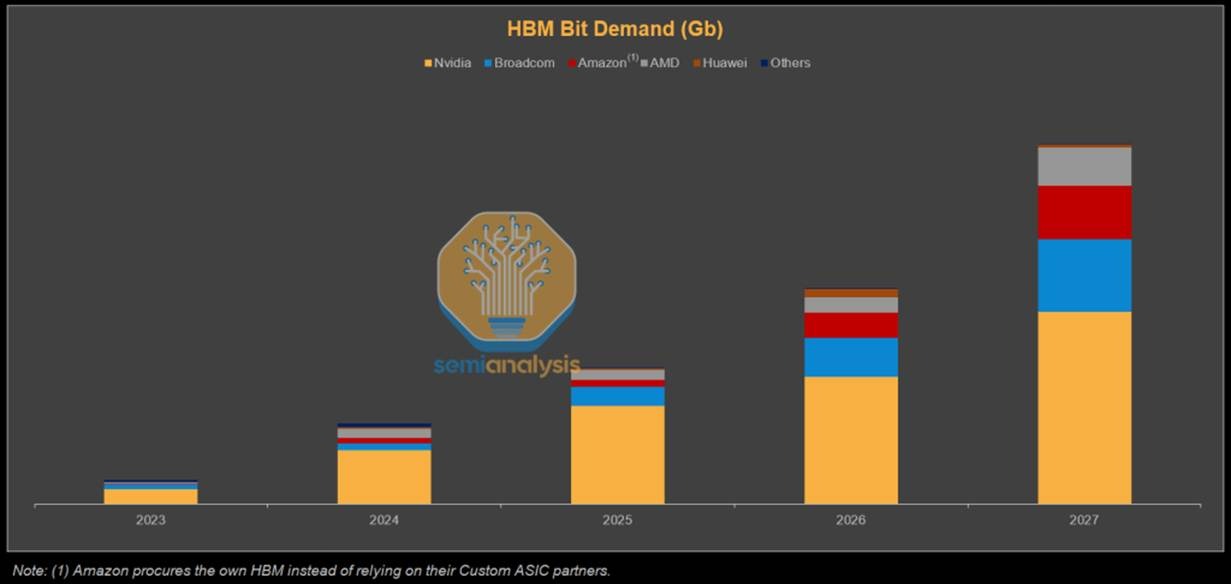
Source: SemiAnalysis
Longer term supply outlook
“I'd say my biggest concern actually is memory. The path to creating logic chips is more obvious than the path to having sufficient memory to support logic chips. That's why you see DDR prices going ballistic.”
“They're building fabs as fast as they can. So is Samsung. They're pedal to the metal. They're going balls to the wall, as fast as they can. It’s still not fast enough.”
Elon Musk, February 2026 (Dwarkesh Patel Podcast)
While memory market forecasts for 2028 and beyond are even more uncertain, if AI proves to be a secular trend that becomes integrated across all facets of society, this should sustain strong memory demand over the longer term. Demand would not only stem from data centres on Earth, but also potentially data centres in space, as well as self-driving cars and humanoids.
The key question then lies on the supply side, where figures like Elon Musk have voiced concerns that production capacity is likely to fail to keep pace with surging demand. Musk has urged both Samsung and Micron to build fabs faster and has said he would guarantee to purchase the output of those fabs. However, he does not think production will match his needs, which is why his proposed TeraFab ambitions extend beyond logic and packaging to include memory.
Nevertheless, TeraFab should not be viewed as a guaranteed solution to ease supply constraints any time soon. Memory manufacturing is highly specialised and requires deep domain expertise, process know-how and execution capability, making the industry extremely difficult to enter. While Musk has a strong track record of entering complex industries which makes success more likely than not, it is not assured. Eventual success would also take considerable time, not only because building, equipping and ramping a fab is a multi-year process, but also because a new entrant must assemble a world-class team, develop process expertise and work through a steep learning curve. Moreover, output may be used primarily to support Musk’s own companies rather than being supplied broadly to third parties.
New supply could also come from existing Chinese suppliers such as CXMT. However, they are generally considered to be several years behind the frontier and geopolitical considerations may make it difficult to participate in existing supply chains. Therefore, it currently looks unlikely that there will be a surprise supply shock in AI-grade memory. As such, if AI demand remains robust and the current build-out continues, supply constraints are likely to persist for many years to come.
Risks to memory demand
One of the larger risks to both the memory sector and the broader AI build-out is energy availability. AI data centres are extremely power-intensive and, given limited growth in power generation and grid capacity across the West, this could constrain deployment. Musk believes that already by the end of 2026 there will be an excess of chips, as there will not be enough available power to turn them all on. It is, however, unclear how power constraints might impact demand and pricing over time, though the effect may be more moderating than destructive, as newer chips are significantly more power efficient, resulting in continued demand as hyperscalers replace older inefficient chips.
In the long run, if orbital data centres become viable, which Musk now believes is three years away, the power constraint would be largely removed. That said, Musk’s timelines are often optimistic, and he himself has said that his timelines are typically set with only a 50% probability of being achieved. Other leaders in the AI space tend to view orbital data centres as something more like a decade away. There may also be other pathways to easing the energy constraints over time, including a faster build-out of nuclear capacity or meaningful breakthroughs in fusion, but these too are likely to take time to scale. As a result, power-related constraints could remain a long-term headwind to AI infrastructure growth and, by extension, the memory market.
Aside from energy, efficiency improvements on both the software and hardware side could moderate memory demand growth. As discussed earlier, architectural innovations such as MoE and distillation are reducing the memory required per unit of useful AI output. If these trends accelerate, for instance, if future models achieve frontier-level performance at a fraction of current parameter counts, the rate of growth in memory demand could slow materially, even if total demand continues to rise. Aggressive quantisation techniques, which have already moved well beyond FP16 to INT8 and INT4 in production inference, further compress memory requirements. On the hardware front, PIM could reduce the need for extreme memory bandwidth by performing certain computations within the memory itself. However, since PIM is being developed by the incumbent memory producers, most notably SK Hynix, it is more likely to enhance their competitive positioning than to disrupt their economics, at least in the medium term.
Finally, there could also be diminishing returns to scaling models, as well as challenges with further AI adoption and monetisation, which could subsequently reduce CAPEX. A scenario in which AI monetisation disappoints and hyperscalers pull back spending, coinciding with the arrival of new fab capacity currently under construction, could produce the kind of oversupply bust that has historically plagued the memory industry.
Conclusion
If the AI secular trend persists, driven by widespread adoption and positive ROI, the memory market could enter a prolonged era of structural tightness rather than repeating historical boom-and-bust cycles. In this scenario, demand would continue to be led by hyperscale data centres, both on Earth and potentially in space, as well as adjacent compute-intensive categories such as full self-driving vehicles and humanoid robotics. This continued demand expansion would keep supply struggling to catch up, compounded by the lengthy timelines for new fabs to become fully operational, thereby maintaining elevated prices and high margins for many years to come. That said, meaningful risks remain, such as energy constraints and potential AI monetisation challenges, which could reduce aggregate memory demand, leading to an oversupply bust. Barring such disruptions, however, the memory market may well be entering a golden age.
At AlphaTarget, we invest our capital in some of the most promising disruptive businesses at the forefront of secular trends; and utilise stage analysis and other technical tools to continuously monitor our holdings and manage our investment portfolio. AlphaTarget produces cutting edge research and our subscribers gain exclusive access to information such as the holdings in our investment portfolio, our in-depth fundamental and technical analysis of each company, our portfolio management moves and details of our proprietary systematic trend following hedging strategy to reduce portfolio drawdowns. To learn more about our research service, please visit https://alphatarget.com/subscriptions/.


